Assiste.com
boardreader - Moteur de recherche (search engine)
cr 22.06.2016 r+ 09.08.2022 r- 20.06.2024 Pierre Pinard. (Alertes et avis de sécurité au jour le jour)
|


.")


Dossier (collection) : Moteurs et métamoteurs de recherche |
|---|
| Introduction Liste Malwarebytes et Kaspersky ou Emsisoft (incluant Bitdefender) |
| Sommaire (montrer / masquer) |
|---|





 Intérêt du moteur pour l'internaute
Intérêt du moteur pour l'internaute
Intérêt du moteur pour les webmasters (SEO)
Moteur de recherche dans les forums de discussion. |

|


BoardReader : comme son nom l'indique, est un moteur de recherche dans les forums de discussion. Indiqué dans cette liste des moteurs de recherche parce qu'il existe et fait ce qu'il prétend faire, mais son comportement tient plutôt, sous ce prétexte, de la ferme de contenus (genre de sites sangsue, se monétisant en exploitant le travail des autres, totalement déréférencés par les « vrais » moteurs de recherche).
BoardReader profite de ses recherches pour capturer des informations personnelles et il les revend à qui les achète (et ils sont nombreux). Il faut absolument lire ses clauses « Vie privée » (en anglais), traduites et reproduites ci-après :
Clauses « Vie privée » (en anglais) du service boardreader
Extraits de leurs clauses - traduction automatique.
Informations collectées
Informations personnelles
Si vous utilisez le site, les informations personnelles vous concernant peuvent être collectées et traitées par les employés de BoardReader. «Informations personnelles» désigne toute information qui peut identifier de manière unique une personne ou être utilisée pour contacter une personne, comme votre nom ou votre adresse e-mail. BoardReader limite généralement l'accès aux informations personnelles vous concernant (sauf mention contraire dans la présente Politique de confidentialité) aux employés dont BoardReader estime raisonnablement avoir besoin pour entrer en contact avec ces informations afin de vous fournir des produits ou services ou de faire leur travail. Créer un compte sur le site n'est pas obligatoire pour utiliser le site, mais si vous créez un compte sur le site, BoardReader recueillera votre nom, adresse e-mail et URL de votre site Web et dans certains cas, titre, adresse, ville, l'état, le pays, le code postal, le numéro de téléphone et l'adresse électronique, ainsi que toute autre information utile aux produits et services de BoardReader, si vous nous les fournissez. Si vous nous envoyez une correspondance, par exemple des courriels ou des lettres, BoardReader recueillera ces informations, y compris les renseignements personnels, dans un fichier qui vous est propre. En général, si vous nous fournissez intentionnellement des informations personnelles, BoardReader les collectera.
De temps à autre, BoardReader peut demander d'autres informations personnelles afin de fournir des fonctionnalités, des fonctions ou des services, mais vous aurez toujours le choix de décider ou non de fournir les informations demandées. Si vous accédez aux parties à accès restreint du site, vous devrez peut-être fournir des renseignements personnels supplémentaires.
Information non identifiable
De plus, BoardReader recueille et compile les informations relatives à votre utilisation du Site qui ne sont pas des informations personnelles telles que l'heure, la date, le type de navigateur, la langue du navigateur, le système d'exploitation, le nom de domaine de votre fournisseur d'accès Internet. (collectivement appelées « Informations non identifiables ») dans le cadre de l'exploitation de ce Site ou au cours de vos activités sur ou de l'utilisation de ce Site.
Partage d'informations
Les informations non identifiables et les informations personnelles vous concernant sont divulguées et partagées avec des annonceurs, des partenaires commerciaux, des sponsors et d'autres tiers dans des circonstances limitées. BoardReader peut divulguer la fréquence des visites sur le site par l'utilisateur moyen. BoardReader peut divulguer des informations à des tiers pour nous aider à effectuer une transaction ou à vous fournir un service (par exemple, empaquetage, envoi et livraison d'achats et d'informations, compensation d'opérations, analyses statistiques des services de BoardReader, services promotionnels et formation). services), ou dans le cadre de discussions sur des fusions et acquisitions.
BoardReader peut partager des données, y compris des informations personnelles vous concernant, avec des sociétés affiliées, des partenaires, des filiales et des sociétés ou des individus de BoardReader qui fournissent des services au nom de BoardReader à travers le monde. Dans la mesure où ces entités ont accès à vos informations, elles auront convenu avec BoardReader de suivre ou ont déjà des pratiques de confidentialité non moins protectrices que les pratiques de BoardReader décrites dans ce document, dans la mesure permise par la loi applicable.
BoardReader publiera des informations, y compris des informations personnelles, en rapport avec toute loi, réglementation ou procédure légale en vigueur (comme un mandat de perquisition, une citation à comparaître, une loi ou une ordonnance d'un tribunal). BoardReader peut divulguer des informations personnelles pour protéger ou faire respecter les droits, la propriété ou la sécurité de BoardReader, ses utilisateurs ou d'autres tiers, y compris la divulgation d'informations avec d'autres sociétés et organisations relatives à la protection contre la fraude et la réduction du risque de crédit.
BoardReader peut fournir des informations personnelles aux entreprises ou aux personnes de confiance de BoardReader pour les traiter à notre place, conformément aux instructions de BoardReader et en conformité avec la politique de confidentialité de BoardReader et toute autre mesure de confidentialité et de sécurité appropriée.
Généralement, et sauf indication contraire au moment de la collecte, BoardReader ne vend ni ne loue aucun des renseignements personnels vous concernant à des tiers. Toutefois, BoardReader peut agréger des informations (rassembler des données sur tous les comptes d'utilisateurs) d'une manière qui crée des informations non identifiables et les divulguer aux annonceurs et autres tiers à d'autres fins marketing et promotionnelles. Dans ces situations, BoardReader ne divulgue à ces entités aucune information personnelle. Certaines informations, telles que votre nom, adresse e-mail, mot de passe, ne sont pas divulguées aux spécialistes du marketing ou aux annonceurs.
Vous pouvez choisir de ne pas autoriser BoardReader à fournir des informations non identifiables à certains partenaires. Visitez networkadvertising.org, aboutads.info et jumptap.com pour prendre des décisions éclairées sur votre vie privée en ligne et mobile et pour vous désengager.
Dans le cas où BoardReader est ou la quasi-totalité de ses actifs sont vendus ou transférés, toutes les informations que BoardReader a à votre sujet peuvent être incluses dans les actifs transférés.
Identité :
Icône :

Nom : boardreader
Nom formel :
Début d'activité : 18.05.2001
Fin d'activité :
Juridique :
La recherche des 3 nationalités possibles (propriétaire, domaine, serveur) est extrêmement importante.
La nationalité induit le droit (la justice - les législations) auquel est confronté l'utilisateur en cas de litige. Ceci est précisé dans tous les contrats que vous acceptez (en cochant une case - ce qui a valeur de signature) avec la société derrière le produit ou service que vous utilisez. Ces contrats et ce droit s'imposent obligatoirement à vous, même si vous ne les avez pas lus.
Exemple de clause folle acceptée par les internautes ne lisant pas les contrats qu'ils signent.Nota :
Les clauses contractuelles ne peuvent s'appliquer qu'entre vous et une personne (physique ou morale [artisan ou société]) juridiquement dument et complètement identifiée, publiant ses codes d'enregistrement dans les registres de son pays (RCS - Registre du Commerce et des Sociétés ou RM - Registre des Métiers ou Préfectures de Police en France (SIREN - Système d'Identification du Répertoire des ENtreprises, SIRET - Système d'Identification du Répertoire des ÉTablissements, etc.), registre de la fiscalité et de la TVA, etc.).
Un contrat avec un site Web est nul et non avenu - un site Web n'est ni une personne physique ni une personne morale. Une clause juridique qui ferait référence à un nom de domaine au lieu de l'identité complète et vérifiable de son éditeur, n'a pas, par essence, d'existence.
Un contrat ne peut être signé avec un fantôme (cas des WHOIS où les registrant sont masqués, dont à cause d'une disposition criminelle du RGPD qui, au prétexte de préserver la vie privée des registrant, anonymise les cybercriminels et les escrocs !).
Régistrant :
Nationalité du régistrant :
Nationalité des serveurs :
Clauses, termes et conditions :
Clauses - EULA (End User Licence Agreement) ou CLUF (Contrat de Licence Utilisateur Final) :
URL de contact Référencement :
e-mail de contact Référencement :
Protection/respect de la vie privée :
Respect de la vie privée :
Utilise le protocole HTTPS (si non, risque sur les données privées par attaque Homme du milieu) :
Nécessite une inscription :
URL de contact Privacy :
e-mail de contact Privacy :
Clauses - Vie privée (Privacy) :
Clauses - Contrôle par l'utilisateur de la gestion des cookies :
Aucune gestion des cookies — Suivez toutes les recommandations de nettoyage et réglages de notre paragraphe 4 ci-dessous.Clauses - Contrôle par l'utilisateur des données privées collectées et de leurs usages (RGPD) :
Suivez toutes les recommandations de nettoyage et réglages de notre paragraphe 4 ci-dessous.
Référencement :
Informations :
En matière de SEO, ne présente aucun intérêt. Il n'existe pas de référencement. Il ne dispose d'aucun Spider (Indexation du Web) ni d'aucun index et fait sa recherche en sollicitant 1 ou plusieurs autres moteurs, au moment de chaque requête.
Il ne retient et affiche que les fils de discussion et les messages de moins de trois mois.
On remarquera que les liens générés dans ses pages de résultats ne comportent pas de clause « rel="nofollow" ».
Date lancement du moteur :
Dispose de son propre crawler :
Aucun. Ni spider ni index. Consulte d'autres moteurs. Est, en ce sens, un métamoteur.Lien (URL) du crawler :
Lien du spider (crawler)Lien(s) de référencement :
|

Les métamoteurs ne sont pas des moteurs de recherche (ils ne disposent pas de leurs propres index), mais des outils relançant vos recherches vers les moteurs traditionnels (Google, Bing, etc.), puis agrégeant et dédoublonnant les résultats, et vous les présentant. Le but est de se faire des revenus, publicitaires ou d'affiliation avec des e-commerces, en exploitant le travail des autres. Lorsque les Google, Bing, etc. s'en aperçoivent (arrivent à les identifier malgré leurs précautions de furtivité), ils ne fournissent plus de résultats à ces métamoteurs qui disparaissent. Certains peuvent consulter les moteurs traditionnels après avoir anonymisé vos requêtes (en passant par des proxys...). Dès que les fournisseurs (Google, Bing, etc.) auront trouvé la source de ces requêtes, ils ne fourniront plus de résultats et les métamoteurs comme DuckDuckGo disparaîtront.
|

Les moteurs de recherche trompeurs et menteurs sont de faux moteurs de recherche dont l'ensemble des résultats apparaissant dans les premières pages n'ont rien de « naturel » et dirigent vers des sites appartenant à l'auteur du moteur de recherche menteur ou avec lesquels il a des relations et intérêts (commerciaux, financiers, crapuleux, idéologiques, etc. ...).
Les moteurs de recherche imposés par certains gouvernements, qui bloquent l'utilisation des moteurs de recherches génériques ou leur interdisent de montrer certains résultats, font partie des moteurs de recherche trompeurs et menteurs.
L'intérêt d'un moteur de recherche est stratégique, dans tous les domaines, à tel point que de nombreuses réflexions ont lieu, dans tous les pays, pour disposer d'un moteur de recherche souverain. Le moteur de recherche est le point d'entrée sur le Web, c'est la fenêtre sur le Web (et c'est un objet de pouvoir du premier cercle). L'argent, le pouvoir, l'idéologie... sont des intérêts majeurs aux yeux de beaucoup : les pays hyper capitalistes masqués sous un pseudo communisme (Chine, Corée du Nord, etc. ...), les dictatures (Afrique, Moyen-Orient, etc. ...), les sectes, les mouvements terroristes, etc. ... et les cybercriminels.
Article complet sur les moteurs de recherche trompeurs et menteurs.
|

Les moteurs de recherche conservent toutes les traces de la navigation WEB de chaque internaute du monde, entre autres en collectionnant les requêtes mais aussi avec une foule d'outils, gratuits ou non, qu'utilisent les Webmasters dans leurs sites WEB, jetant ainsi tous leurs visiteurs dans les rets de ces espions (par exemple les WEB-Bug (hit parade des utilisateurs de WEB-Bug), les filtres du WEB (Google Safe Browsing, Microsoft SmartScreen, etc.) incérés nativement dans les navigateurs WEB, les outils de statistiques utilisés par tous les sites WEB dont, principalement, ceux de Google (Google Analytics, Google JSAPI Stats Collection, Google Trusted Stores, Google Website Optimizer), etc. et une foule de services (principe d'encerclement). Ce type d'espionnage est défendu becs et ongles, car il permet de personnaliser les publicités affichées (la publicité est le modèle économique d'un Web gratuit - sans publicité, les sites non marchands [les sites de contenu, comme Assiste.com] disparaissent ou entre dans un modèle payant).
Il n'y a pas que la construction des clickstream (« Flux de clics ») qui galvanise la révolte des internautes désireux de protéger leurs vies privées.
Les entêtes de vos requêtes HTTP sont un véritable Cheval de Troie dans votre vie privée.
Tous les opérateurs défendent leur besoin viscéral de nous espionner au plus haut niveau (Les cinq cercles du pouvoir).
L'affaire Prism et Cie (les révélations d'Edward Snowden) a alerté/réveillé les consciences, à tel point que l'Union Européenne à pondu un texte particulièrement protecteur : le RGPD - Règlement Général sur la Protection des Données.
Etc.
|

En Europe, dans tous les 27 pays de l'Union, depuis le 5 mai 2018, le RGPD (Règlement Général sur la Protection des Données) impose à tous les sites WEB, avec extraterritorialité (applicable à tous les opérateurs WEB du monde, quelque soit leur pays, entrant en relation avec des internautes des pays européens) d'offrir à leurs visiteurs/utilisateurs :
Pour les nouveaux visiteurs/utilisateurs d'un site WEB, l'Opt-In (le choix préalable d'accepter ou de refuser d'entrer dans un mécanisme, dont celui du tracking [pistage, poursuite, surveillance, espionnage]).
Pour les précédents (anciens) visiteurs/utilisateurs d'un site WEB, l'Opt-Out (le choix de poursuivre ou de cesser d'être victime d'un mécanisme dans lequel ils sont entrés sans le savoir et sans savoir qu'il s'exerce depuis leur toute première connexion au WEB, sur l'Internet, dont celui du tracking [pistage, poursuite, surveillance, espionnage]).
Le règlement a été adopté le 27 avril 2016. Les sites WEB ont donc eu une période de transition de plus de 2 ans pour développer et offrir ce choix. Il y a des résistances, car la publicité est le modèle économique du WEB et la publicité ciblée, grâce à l'analyse de votre comportement, est plus efficace (plus rémunératrice) que la publicité non ciblée (la publicité numérique représente des centaines de milliards d'euros et le commerce des données privées espionnées/collectées également).
Nota :
Les annonceurs publicitaires et autres traqueurs ne sont pas en relation directe avec les sites WEB. Ils confient ce travail et leurs budgets à une régie publicitaire à laquelle ils adhèrent (des alliances professionnelles).
Il y a donc deux approches pour se conformer au RGPD :
Ceux qui s'y conforment de manière compliquée en recommandant, dans des pages d'explications invraisemblablement longues et incompréhensibles, l'usage des Opt-Out par les alliances professionnelles des régies publicitaires et autres traqueurs(qui ne fonctionnent pas souvent et sont sujets à désactivation dès que l'internaute vire ses cookies).
Ceux qui s'y conforment de manière simple et instantanée avec des solutions comme :
Les moteurs de recherche sont, avec les réseaux sociaux, les plus puissants espions des personnes physiques au monde et les membres du premier cercle du pouvoir sur le WEB.
Utilisez toujours les outils d'Opt-Out des alliances, qu'il y ait ou non, pour chaque site visité, une solution simple.
Compléter par notre procédure de protection du navigateur, de la navigation, et de la vie privée.
|

Les navigateurs WEB peuvent, à leur lancement, s'ouvrir sur une page WEB quelconque (au choix de l'utilisateur). Par défaut, la page WEB de démarrage du navigateur WEB est celle d'un moteur de recherche. Il finit par y avoir confusion entre navigateurs WEB et moteurs de recherche sur le WEB.
Navigateurs WEB
Un navigateur Web (Firefox, Microsoft Internet Explorer, Microsoft Edge, Opera, Google Chrome, Safari, K-Meleon, etc.) est une application qui s'exécute localement, dans votre appareil. Nous sommes dans l'un des mondes d'Internet, le WEB, un monde dit « client – serveur » et le navigateur Web est le « client » qui :
Fait des requêtes (transmet vos requêtes) aux serveurs
Interprète et affiche les contenus visités (les pages Web écrites dans le langage HTML et utilisant de nombreuses technologies comme JavaScript grâce à son « moteur de rendu » et des technologies propriétaires comme la technologie scélérate ActiveX ou Flash).
Exécute des centaines de fonctions locales avec du code open source (cas de Firefox) ou du code totalement privé/secret et suspect (cas de Google Chrome)
Virtualisation des navigateurs Web
Certains tentent de virtualiser le comportement d'un navigateur WEB afin qu'il ne s'agisse plus d'une application locale, mais d'une fonction distante, dans le genre des SaaS - Software as a Service.
L'un des arguments avancés est la bêtise des tablettes qui n'ont ni intelligence locale ni stockage local de données.
Il s'agit surtout de nous empêcher de contrôler le comportement du navigateur Web et de nous empêcher de nous protéger de l'espionnage et de la collecte de données privées.
La virtualisation locale du navigateur WEB (sandboxing), dans un réseau local (entreprise...), est autre chose et relève de la sécurité en assurant l'isolement des postes de travail se trouvant dans une DMZ (zone démilitarisée - moins protégée), au-delà d'une infrastructure centralisant la sécurité.
Moteurs de recherche
Les moteurs de recherche sont des services d'indexation du contenu du Web afin de nous permettre de trouver les ressources (les pages Web, etc.) qui répondent « le mieux » à nos requêtes.
Le moteur de recherche est un service distant, se présentant comme un site Web exécutant, à distance, une fonction et nous en communiquant le résultat. Il est consulté/utilisé :
Grâce à un navigateur Web
Grâce à l'appel à sa fonction dans un site Web quelconque. Ainsi :
Le site Web Assiste.com utilise, en interne, le moteur de recherche Qwant
Le site Web YouTube utilise, en interne, le moteur de recherche Google Search
|

Utilisez les sitemap, n'attendez pas les crawler (mais, à partir du moment où en commence à utiliser les sitemap, il ne faut plus les laisser en sommeil car le crawler cesse pratiquement de visiter le site).
Déclarez le chemin d'accès à votre sitemap dans le fichier robots.txt
Utilisez les flux RSS
Utilisez les propriétés Open Graph
L'URL de chaque page devrait contenir des mots-clés du contenu de la page
La balise title devrait contenir plus de 40 caractères et, au maximum, 65 caractères (espaces compris), avec des mots-clés
La balise meta description devrait contenir plus de 100 caractères et, au maximum, 200 caractères (espaces compris), avec des mots-clés
La balise meta keywords est totalement abandonnée et ignorée par tous les moteurs de recherche à cause du bourrage de mots-clés (Stuffing keywords). Déjà, en 2003, presque plus aucun moteur ne les lisait (voir mon ancien tableau de 2003 à http://terroirs.denfrance.free.fr/p/webmaster/comparatif_moteurs.html.
Une balise H1 devrait commencer chaque page et avoir un maximum de 55 caractères (espaces compris)
Jamais de contenu dupliqué (DC - Duplicate content). Si deux pages ont le même contenu avec des URL différentes, utilisez une redirection permanente (301) de l'une sur l'autre ou, à la rigueur, la balise canonical
Jamais de fermes de liens, c'est le meilleur moyen, non pas d'être renvoyé dans le fond des classements, mais d'être purement et simplement banni du référencement (adieu le site sous son nom de domaine actuel). Voir également les fermes de contenu.
Jamais de plagiat. Il y a des outils automatiques de recherche de plagiat et les moteurs de recherche savent s'en servir. Voir Recherches de plagiats et copieurs.
Jamais de cloaking - c'est le déréférencement direct
Jamais de bricolage (boucles temporisées, clics automatiques, etc.) pour augmenter les stats ou les revenus. C'est détecté et, non seulement le site est banni, mais les revenus sont confisqués.
Avoir un certificat SSL
Etc.
|

Les résultats d'une requête faite à un moteur de recherche (SERP – Search Engine Results Page – Page de résultats d'un moteur de recherche) sont les pages affichées en réponse à la question d'un chercheur (un internaute).
Ces pages sont essentiellement composées de deux types de résultats :
Les résultats de la recherche organique
La recherche organique, c'est-à-dire les résultats récupérés par l'algorithme du moteur de recherche parmi tous les liens (plusieurs milliards de milliards), sur le Web, qui semblent répondre plus ou moins bien/complètement à la requête. C'est la liste des résultats renvoyés par le moteur de recherche en réponse aux mots-clés soumis par le chercheur. Cette liste est ordonnée par pertinence décroissante selon les méthodes/algorithmes de classement propres au moteur sollicité (par exemple le « PageRank » de Google).Des résultats rémunérateurs constituant le modèle économique du moteur :
Un moteur de recherche n'est jamais gratuit. S'il vous semble gratuit, si vous croyez l'utiliser gratuitement, en réalité l'espionnage permanent de ce qu'est votre vie (ce que vous faites, ce que vous regardez, là où vous allez sur le Web, là où vous allez physiquement, avec qui, ce que vous achetez, ce à quoi vous vous intéressez dans tous les domaines, etc.) permet de vous profiler, de vous connaître mieux que votre mère ne vous connaît, mieux que vous ne vous connaissez vous-même, pour vous proposer des apparences de résultats de recherche qui sont, en réalité, de faux résultats que des annonceurs payent au moteur de recherche (qui doit bien gagner sa vie, et il le fait également en vendant votre vie privée à d'autres).
Si le produit est gratuit, c'est que vous êtes le produit.
Si le service est gratuit, c'est que vous êtes le service.Des résultats provenant de mécanismes de sponsoring (liens sponsorisés – des sites Web payent le moteur pour apparaître en premier dès que certains mots-clés sont dans la requête (par exemple le service « AdWords » de Google). Appelé « SEM » (Search Engine Marketing), c'est du marketing via les moteurs de recherche. Cela permet d'apparaître en première page, dans la colonne de droite (insertions publicitaires) ou en haut de page. Les mots-clés sont en permanence, voire en temps réel, mis aux enchères et celui qui paye le plus apparaît en premier, etc. Voir, par exemple, la régie française SMART AdServer et sa plateforme d'Ad-exchange (plateforme d'achat/vente d'espaces publicitaires) pratiquant le Marketing Programmatique et le Real Time Bidding - RTB (un système d'enchères en temps réel dans le monde de la publicité numérique [en ligne]).
Des résultats provenant de régies publicitaires (par exemple la régie Google AdSense qui est, de très loin, la première régie publicitaire au monde).
L'annotation « annonce » ou « publicité » ou « annonce sponsorisée », etc. est obligatoire.
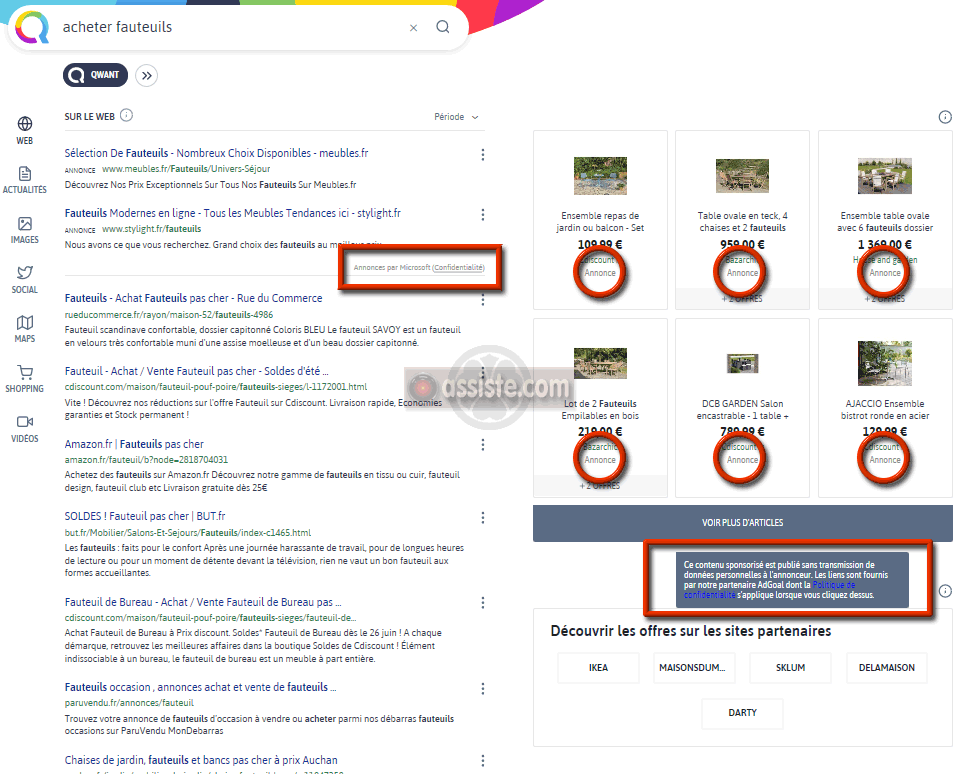
Annonces et publicités dans les moteurs de recherche (résultats non naturels - non organiques)
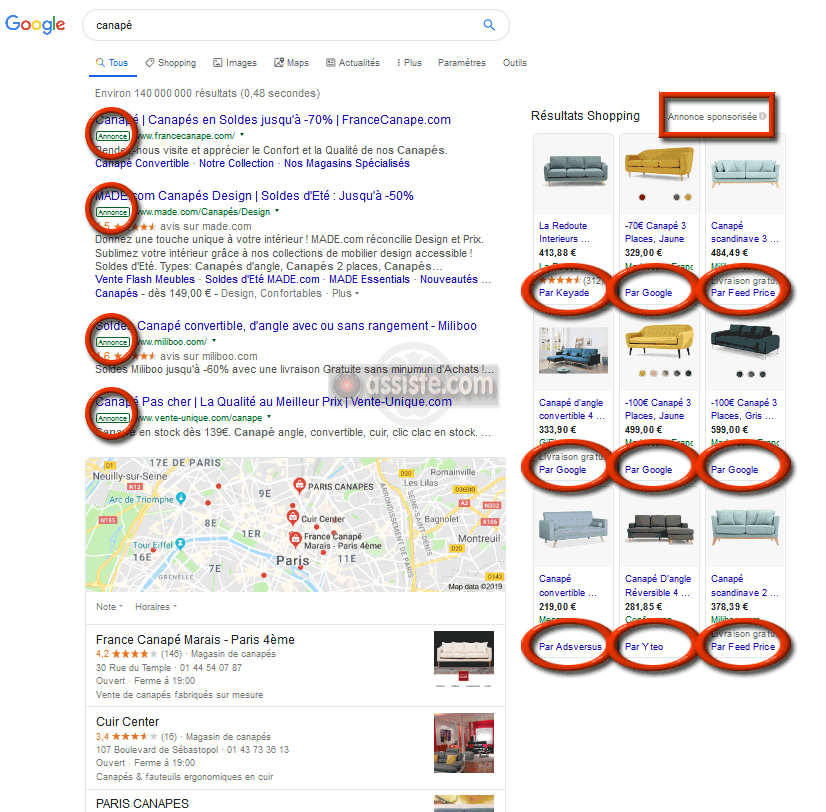
Annonces et publicités dans les moteurs de recherche (résultats non naturels - non organiques)


